




作為中華文明的重要載體,古漢字在數(shù)千年演變過程中形成了甲骨文、金文、篆書、隸書等多樣化形態(tài),其結(jié)構(gòu)特征與現(xiàn)代漢字存在顯著差異。這些文字廣泛留存于古籍文獻(xiàn)、碑刻拓片、書法作品等載體中,其準(zhǔn)確識別往往需要深厚的古文字學(xué)專業(yè)知識。隨著深度學(xué)習(xí)技術(shù)的發(fā)展,卷積神經(jīng)網(wǎng)絡(luò)(CNN)與視覺Transformer(ViT)被廣泛應(yīng)用于各類漢字識別。然而現(xiàn)有研究多集中于單一字體或載體類型漢字識別,如針對甲骨文或簡牘帛書的專項(xiàng)識別。這種研究范式存在明顯局限性:一方面難以適應(yīng)不同歷史時期、不同地域古漢字在結(jié)構(gòu)和形態(tài)上的巨大差異;另一方面無法滿足實(shí)際應(yīng)用場景中多類型漢字混合識別、多載體聯(lián)合處理的現(xiàn)實(shí)需求。同時,自然場景下的古漢字識別還面臨三大核心難題:一是字符類型復(fù)雜多樣,涵蓋不同歷史時期的多種漢字;二是待識別字符數(shù)量龐大,系統(tǒng)性處理難度高;三是應(yīng)用場景分布廣泛且環(huán)境復(fù)雜。這些因素共同構(gòu)成了制約當(dāng)前古漢字識別研究發(fā)展的關(guān)鍵瓶頸,亟需通過構(gòu)建大規(guī)模多類型漢字?jǐn)?shù)據(jù)集和開發(fā)通用識別模型來突破。

6月19日,Nature旗下期刊npjheritagescience在線發(fā)表我校人文學(xué)院數(shù)字人文專業(yè)博士生王釗江(指導(dǎo)教師吳夏平教授)與湖州師范學(xué)院、華南理工大學(xué)聯(lián)合開展的一項(xiàng)針對多樣化應(yīng)用場景古漢字識別的重要成果,題為“HUNet: hierarchical universal network for multi-type ancient Chinese character recognition”(https://www.nature.com/articles/s40494-025-01813-9)。論文提出了一種面向中國八體漢字識別的輕量化網(wǎng)絡(luò)模型。該模型針對書法掛畫、碑刻石刻、楹聯(lián)匾額等多樣化應(yīng)用場景,實(shí)現(xiàn)了對古代漢字的精準(zhǔn)高效識別。通過創(chuàng)新的網(wǎng)絡(luò)架構(gòu)設(shè)計(jì),模型在保證識別準(zhǔn)確率的同時顯著降低了計(jì)算復(fù)雜度,具備良好的跨平臺適配性,可靈活部署于各類終端設(shè)備。

論文基于《通用規(guī)范漢字表》構(gòu)建了超900萬樣本量的Multi-Type Ancient Chinese Character Recognition(MTACCR)數(shù)據(jù)集。MTACCR數(shù)據(jù)集包含多種類型漢字圖像,包括原始掃描圖像和經(jīng)過預(yù)處理的二值化字形圖像。與現(xiàn)有相關(guān)數(shù)據(jù)集相比,MTACCR數(shù)據(jù)集在字符數(shù)量、古漢字類型、數(shù)據(jù)規(guī)模和圖像多樣性方面均實(shí)現(xiàn)了顯著擴(kuò)展和豐富。為了滿足不同應(yīng)用場景下古漢字的快速高效識別,論文進(jìn)一步提出Hierarchical Universal Network(HUNet)。HUNet采用層次化網(wǎng)絡(luò)架構(gòu),通過不同階段關(guān)注漢字的局部形狀和幾何特征、關(guān)鍵位置和筆畫關(guān)系、空間結(jié)構(gòu)關(guān)系,實(shí)現(xiàn)了模型參數(shù)利用效率的提升,使得模型網(wǎng)絡(luò)在保持低參數(shù)量和高吞吐量的同時實(shí)現(xiàn)了較高的識別性能。
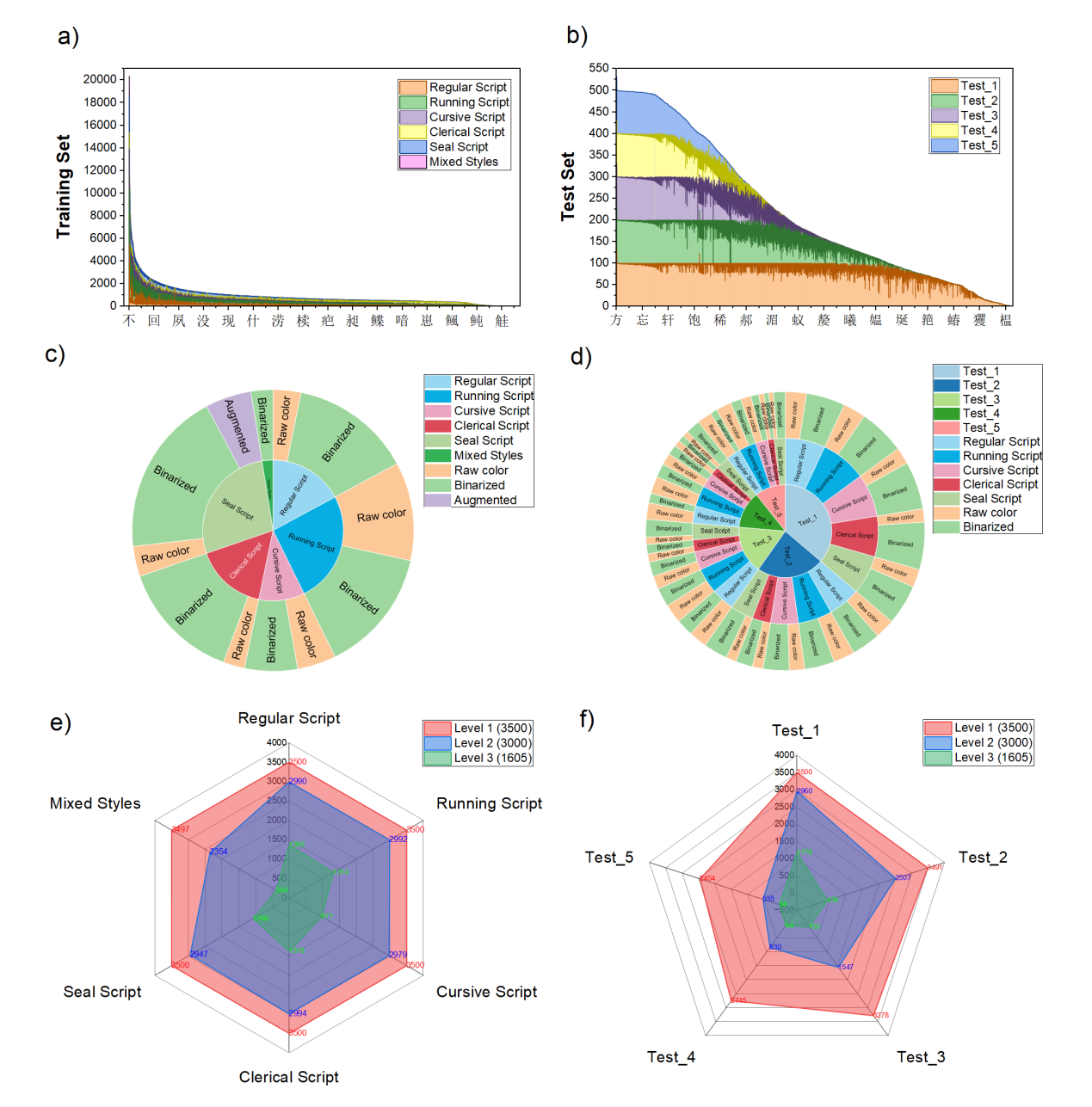
MTACCR數(shù)據(jù)集統(tǒng)計(jì)
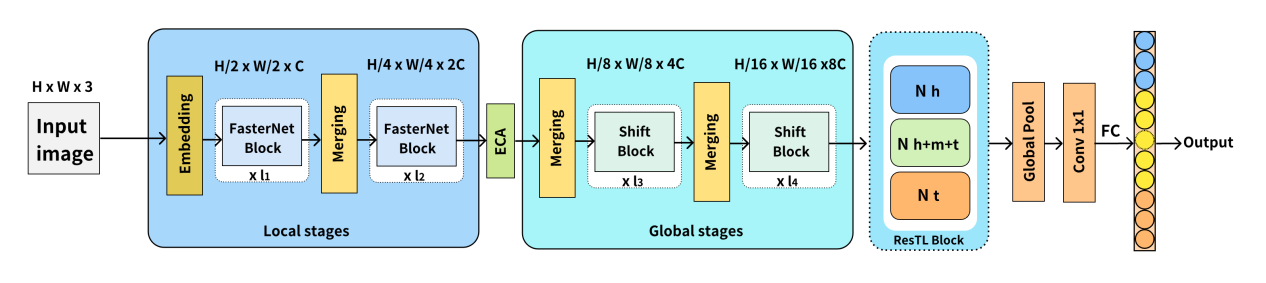
HUNet宏觀網(wǎng)絡(luò)架構(gòu)
實(shí)驗(yàn)結(jié)果表明,HUNet模型在MTACCR數(shù)據(jù)集和多場景古漢字識別(MACR)數(shù)據(jù)集上的測試性能表現(xiàn)優(yōu)異。與其他參與評估的高效CNNs和ViTs模型相比,HUNet在參數(shù)量相當(dāng)?shù)那闆r下實(shí)現(xiàn)了更高的識別性能,或在識別性能相當(dāng)?shù)那闆r下保持了更低的參數(shù)量,同時維持了較高的計(jì)算吞吐量。在MTACCR Test_1測試集上(包含60萬測試樣本),HUNet_48的Top-1準(zhǔn)確率達(dá)到94.23%。在MACR測試集上,使用MTACCR訓(xùn)練的HUNet模型的Top-1準(zhǔn)確率提升了9.64%。此外,HUNet還可有效擴(kuò)展到非漢字古代文本識別任務(wù),在DeepLontar和ALPUB_v2兩個數(shù)據(jù)集上表現(xiàn)出一定的競爭優(yōu)勢。
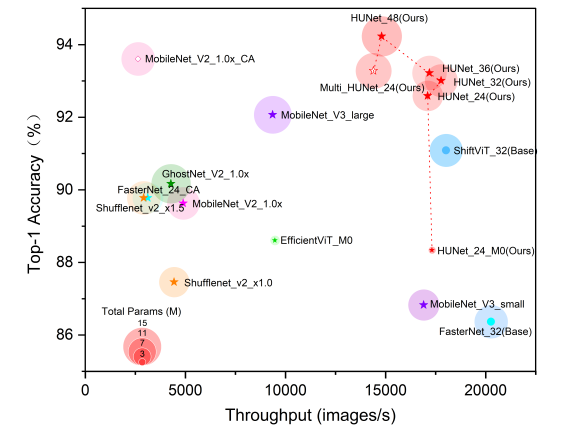
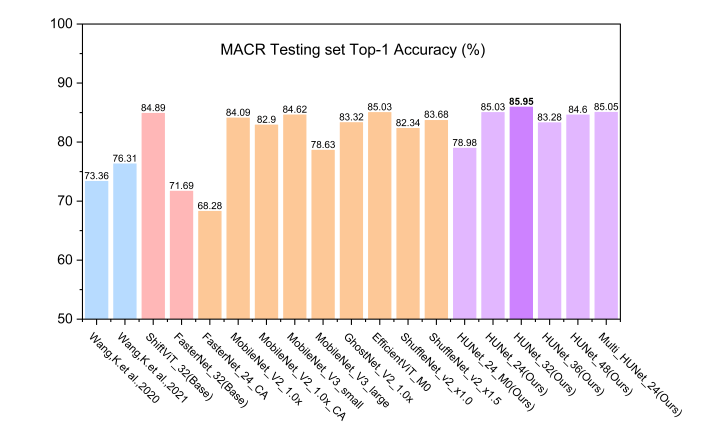
HUNet與其它高效模型性能對比
在論文提出的輕量化網(wǎng)絡(luò)模型基礎(chǔ)上,研究團(tuán)隊(duì)進(jìn)一步開發(fā)了智能云端古漢字識別小程序。該小程序融合場景文本檢測算法,能夠?qū)崿F(xiàn)對多樣化場景中各類古漢字的實(shí)時精準(zhǔn)識別,為用戶提供便捷高效的古文字識別服務(wù)。論文開源地址:https://github.com/1602353775/HUNet

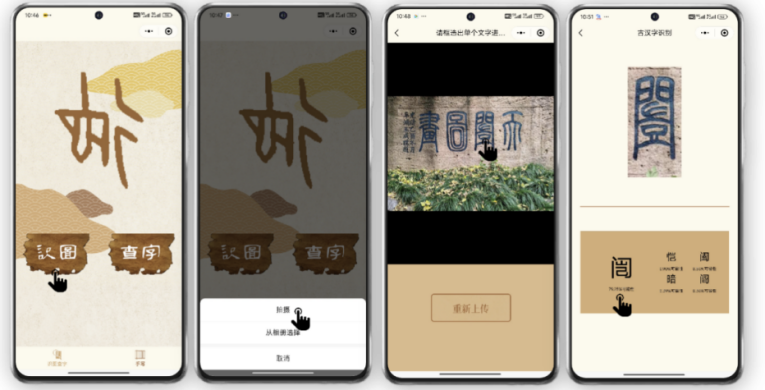
智能云端古漢字識別小程序
上海師范大學(xué)人文學(xué)院聚焦服務(wù)國家重大戰(zhàn)略,以深化新文科建設(shè)內(nèi)涵為切入點(diǎn),高度重視數(shù)字人文學(xué)科建設(shè)。2020年成立數(shù)字人文研究中心,2021年獲批上海市“數(shù)字人文資源建設(shè)與研究”重點(diǎn)創(chuàng)新團(tuán)隊(duì),2022年獲批數(shù)字人文專業(yè)博士點(diǎn),2023年開始招收數(shù)字人文專業(yè)博士生。近年來,團(tuán)隊(duì)已出版“數(shù)字人文教材系列”“數(shù)字人文研究叢書”等多種著作,在國內(nèi)外重要學(xué)術(shù)刊物發(fā)表論文多篇,為數(shù)字人文專業(yè)人才培養(yǎng)夯實(shí)了基礎(chǔ)。
(供稿、圖片:人文學(xué)院)





 徐匯校區(qū):上海市徐匯區(qū)桂林路100號
徐匯校區(qū):上海市徐匯區(qū)桂林路100號